Si te gusta el artículo difúndelo por favor: ¡Compartir es ganar!
La optimización es un proceso controvertido dentro del algorithmic trading, tiene detractores y defensores por igual. La optimización consiste en la búsqueda de aquellos valores óptimos de determinadas variables que satisfacen uno/s target prefijado/s (máximo beneficio por ejemplo). ¿Por qué usamos un estocástico de 14 períodos y no de 21? La optimización puede ayudarnos a decidirlo. Es un proceso intensivo de prueba error que va comprobando qué resultado hubieran obtenido en los datos históricos una determinada combinación de parámetros. Hay varios tipos de optimización y diversos procedimientos para optimizar pero no son el objeto de este artículo.
Su peligro es que esta búsqueda obtenga un resultado que si bien satisfaga los targets que hemos prefijado, éste no sea fruto de un pauta estadística sólida si no de una casualidad estadística. ¿Habéis oído aquello de que hasta un reloj estropeado es capaz de dar la hora correcta dos veces al día? Si el reloj está parado a las 6 y justo a esa hora miramos el reloj podemos pensar que el reloj funciona perfectamente. Pero no es así, sencillamente lo hemos mirado casualmente a la hora en que está parado. Algo parecido puede pasar con unos determinados parámetros de nuestro sistema. El optimizador nos dice que son los que mejor satisfacen nuestro target (por ejemplo los que más dinero han ganado en el histórico) pero lo que nosotros queremos saber realmente es si estos parámetros y nuestro sistema seguirán ganando dinero en el futuro, no en el pasado. ¿Y cómo conseguimos esto? Pues siento deciros que es imposible saberlo con certeza, y este es el principal argumento de los detractores de la optimización para no usarla. La sobre-optimización o curve fitting es un riesgo real, es fácil ajustarse al a curva, y debemos trabajar para minimizarlo lo máximo posible, pero en mi opinión, esto no justifica no usarla ya que es una herramienta demasiado potente para prescindir de ella.
Los defensores de la optimización afirmamos que disponemos de diversas herramientas para evaluar la robustez, así como experiencia para fomentarla en el diseño. Defino robustez como la capacidad para mantener en el futuro los datos de performance obtenidos con datos históricos optimizados. Además, no optimizar es renunciar a que el sistema se adapte a la especificidad que tiene cada activo y timeframe. Esto ha hecho que con el paso del tiempo cada vez queden menos detractores de la optimización, centrándose más el debate en que tipo usar, con qué intensidad y sobre todo el procedimiento utilizado, que es donde radica realmente la clave.
A título de ejemplo voy a explicaros resumidamente el procedimiento de optimización que hemos seguido con SERSAN-IBEX-01. Este es un sistema que funciona en el futuro del Ibex en barras diarias y hemos usado una penalización entre comisión y slippage de 80€ por trade (ida y vuelta). Esto implica que vamos a tener una muestra de trades relativamente pequeña, o lo es lo mismo, la significación estadística necesaria para verificar que la performance histórica es robusta va a ser realmente complicada de obtener. Pensar que desde el año 2000 tenemos solamente unas 3200 barras diarias. Aquí el riesgo de curve fitting es realmente alto.
Los primeros estudios los hicimos con datos desde el 2003 porque desde esa fecha tenemos la base de datos ajustada en cada vencimiento del futuro. Ya sabéis que los futuros vencen ya sea mensual o trimestralmente, y esto suele provocar gaps “falsos” en el gráfico continuo de ese futuro, el día en que se cambia de contrato. Siempre que sea posible debemos trabajar con datos ajustados y así lo hicimos de entrada. Aquí podéis ver el artículo inicial con los datos de performance in-sample y out-sample del sistema, con los parámetros que habíamos elegido entonces:
http://sistemasdetrading.info/nuestro-primer-sistema-publico/
No obstante, en una segunda fase utilizamos la base de datos no ajustada ya que entonces teníamos datos desde 1994 y los vencimientos del Ibex no provocan grandes saltos en el gráfico continuo. Al ser un sistema de gráfico diario no vamos sobrados precisamente de datos, preferimos perder “precisión” para ganar robustez. El principal motivo de este cambio es que con datos desde 1994 la optimización mediante Walk Forward (WFO) es ya posible, mientras que desde el 2003 es imposible por falta de muestra.
¿Pero qué es la optimización Walk Forward? Esta es la concepción clásica del proceso Walf Forward:
1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
3 años Optimizados | Externa1 | Externa2 | Externa3 | ||||||
3 años Optimizados | Externa1 | Externa2 | Externa3 | ||||||
3 años Optimizados | Externa1 | Externa2 | Externa3 | ||||||
3 años Optimizados | Externa1 | Externa2 | Externa3 | ||||||
3 años Optimizados | Externa1 | Externa2 | Externa3 | ||||||
3 años Optimizados | Externa1 | Externa2 | |||||||
3 años Optimizados | Externa1 | ||||||||
3 años Optimizados | |||||||||
TOTAL MUESTRAS EXTERNAS | 1 | 2 | 3 | 3 | 3 | 3 | 3 | ||
Quedaros con la idea no con el número de muestras externas ni con los años o el tamaño de los periodos.
Resumiendo mucho es un proceso que va haciendo sucesivas optimizaciones en determinados periodos del histórico (la llamamos in-sample) que luego aplica a otros periodos de datos sin optimizar (la llamamos out-sample o prueba externa). Es un proceso realmente complejo que antiguamente hacíamos con Excel aunque ahora ya disponemos de herramientas muy potentes que automatizan mucho el proceso. Debemos elegir el rango de porcentaje de datos que dejamos en out-sample (suele rondar 10-30%) y el rango de periodos out-sample que queremos tener, o dicho de otra forma, el número de “runs” o periodos optimizados que habrá en el histórico. Por ejemplo:
| Cluster Analysis Settings | Start | End | Inc |
| Out-Of-Sample % | 5 | 30 | 5 |
| Walk Forward Runs | 5 | 12 | 1 |
Para este ejemplo hemos elegido el test con Out-sample%=10 y Runs=5.
Una de las ventajas de este proceso es que te permite obtener la curva de resultados para cada test y sus estadísticos con datos no optimizados que es lo más parecido que existe a la operativa real. Los cinco periodos a la derecha de las líneas son out-sample, es decir, todos no optimizados:
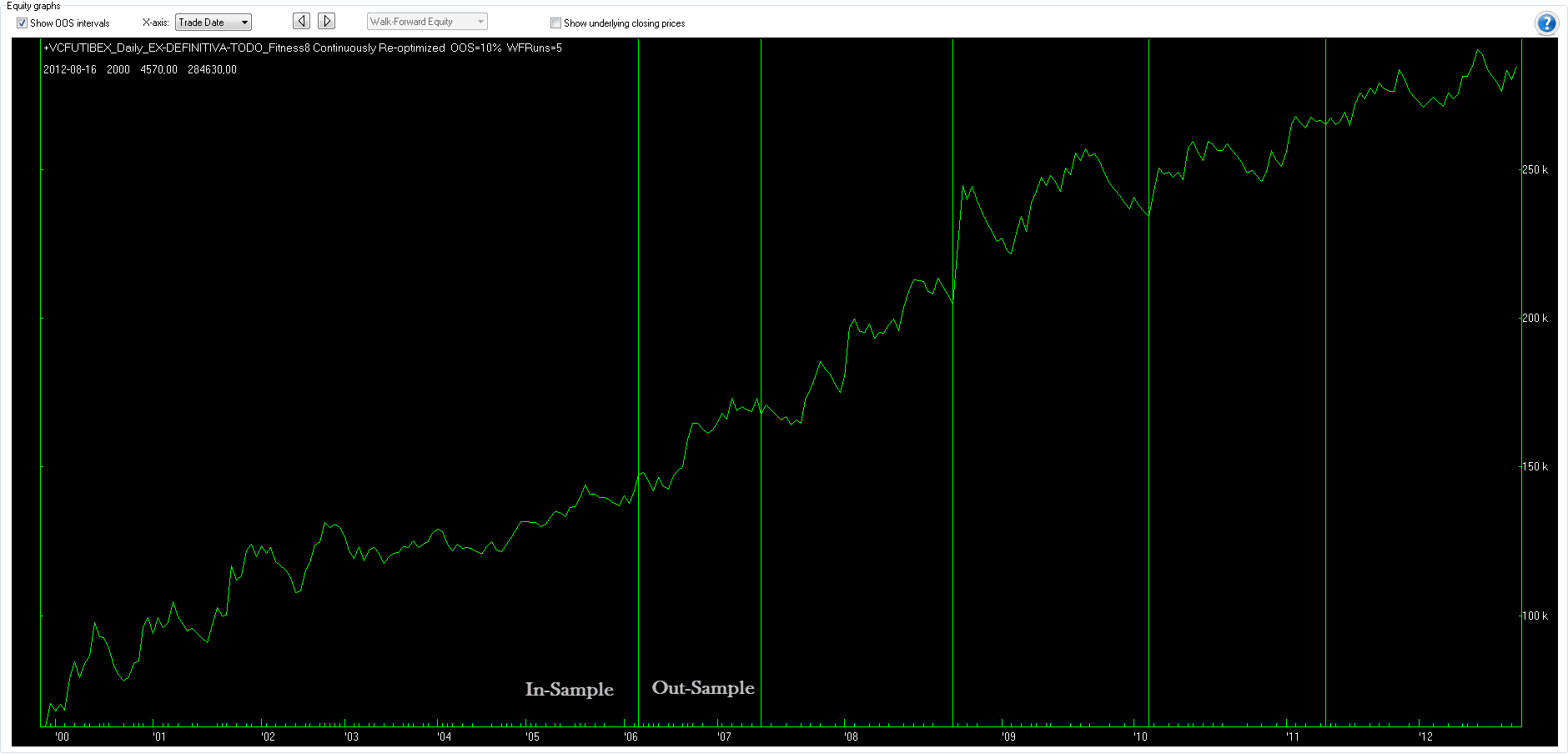
Fijaros ahora en el performance que incluye solo los periodos out-sample (los cinco que veis en el chart de arriba) es decir, no optimizados. Sin duda la operativa real es la auténtica prueba de fuego y ni aun con todos estos test WF tendremos la certeza de que el sistema ganará dinero. Pero sin duda alguna, esto es lo más parecido a simular la operativa real utilizando datos históricos y es una buena orientación de lo que podemos esperar de este sistema en el futuro:
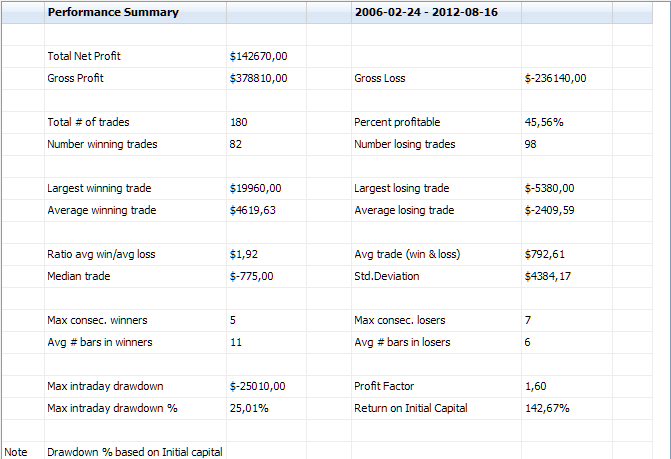
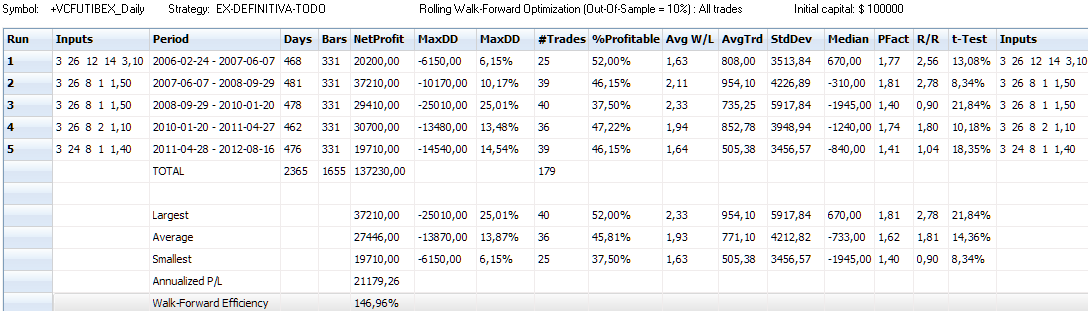
A continuación podéis ver la tabla con los estadísticos de estos cinco períodos, todos out-sample, es decir, no optimizados:
La imagen siguiente muestra los inputs y estadísticos in-sample del mismo proceso que el chart anterior:
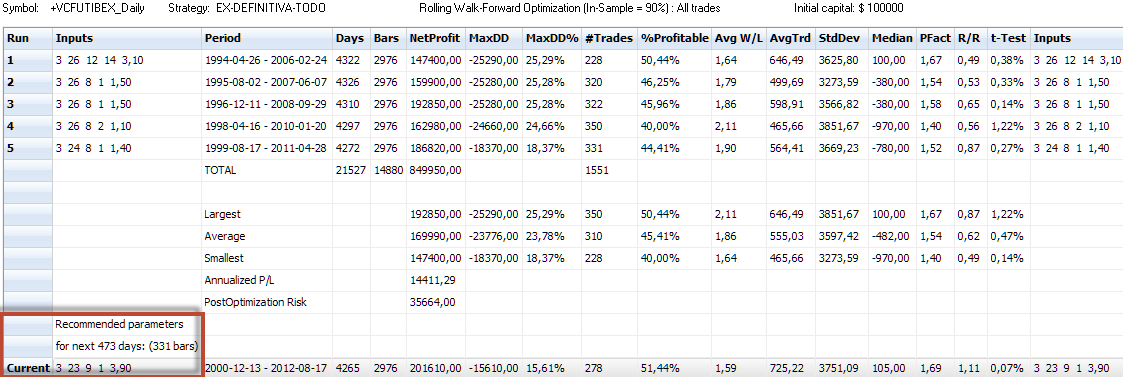
Fijaros en el rectángulo rojo. Una vez damos con la combinación de Out-sample% y Walk Forward Runs más robusta entre todos los test, podemos saber cuales son los parámetros que deberían usarse para el siguiente periodo. Así, este sofisticado proceso nos permite verificar la robustez de nuestro sistema (su principal función) ya que hacemos muchas pruebas de walk forward a la vez, y también si se desea nos permite determinar los mejores parámetros para el siguiente periodo. En este caso para los siguientes 473 días. También se pueden utilizar los parámetros más repetidos en los sucesivos runs y/o en los otros tests, ayudándonos de las pruebas de sensibilidad (como afecta a los resultados variar los parámetros al alza o la baja)
Todas estas tablas son de datos totalmente reales de uno de los análisis WFO que hemos hecho a SERSAN-IBEX-01. El proceso de verificar la robustez es siempre el más importante, especialmente en un sistema diario. Este procedimiento de stress es mucho más complejo, solo he explicado brevemente en qué consiste y su principal utilidad. Quizá dentro de un tiempo haga otro artículo profundizando en detalle en este imprescindible proceso.
La robustez de este sistema es extraordinaria, en bastantes periodos de test distintos el sistema gana más en el periodo out-sample que en el in-sample y en la gran mayoría más del 50% que es el mínimo considerado como aceptable, mantiene DD moderados, es consistente, y pasa con nota prácticamente todas las pruebas de test distintos.
Con la robustez verificada nos sigue quedando pendiente la fijación de los parámetros para operar con él. Podemos usar los que sugiere el WFO o utilizar un método más convencional como sería optimizar todo el histórico junto pero dejando la última parte del histórico (20 o 30%) sin optimizar (out-sample) para ver que resultados obtiene en datos no optimizados. Tras analizar en profundidad múltiples optimizaciones WF y convencionales, nos hemos decantado por este último método porque si bien las pruebas del WFO demuestran su gran robustez y consistencia ante el cambio de parámetros, la muestra sigue siendo relativamente pequeña para ir consiguiendo runs estadísticamente significativos. Fijaros en la tabla out-sample publicada, en la columna t-Test. Obtenemos una media del 14.36% que considero un poco alto. Además, como sistema robusto que es, ciertamente hay muchas zonas con parámetros buenos, y los que hemos elegido están en los primeros puestos tanto con datos in-sample como con datos out-sample, lo que muestra la estabilidad que tienen los parámetros elegidos en todo el periodo y su gran robustez.
Y todo esto solo para la primera versión, sigue pendiente una posible mejora que creemos implementaremos, pero para eso antes hay que verificar su robustez que es lo más importante, y estamos en ello. Recordar, es fácil conseguir un buen performance con datos históricos, lo difícil es mantenerlos en el futuro, y para eso las pruebas de robustez son básicas. Hay otras maneras de buscar y/o verificar la robustez pero el WFO es sin duda una de las mejores.
Mañana publicaremos el artículo semanal de resultados y aprovecharé para pegaros la performance de la combinación de parámetros que finalmente hemos elegido.
Si te ha gustado este artículo no olvides difundirlo por favor: ¡Compartir es ganar!
Sergi Sánchez
Síguenos en twitter @sersansistemas
Nuestro blog: www.sistemasdetrading.info
Nuestra web: www.sersansistemas.com